下载啦:请放心下载,安全无病毒!
软件提交最近更新 热门排行 v3.02.02 官方版")
0%
0%
Tesseract-OCR(文字识别软件) v3.02.02 官方版
- 授权方式:免费软件
- 软件类型:国产软件 / 文字处理
- 软件大小:39.1 MB
- 推荐星级:

- 软件版本:v3.02.02 官方版
- 运行环境:WinXP, Win7, Win8, Win10
- 更新时间:2021-04-15
本地下载文件大小:39.1 MB
- 点击评论
本地下载文件大小:39.1 MB
tesseract ocr是一款识别率的图像识别软件,软件借助先进的文字识别技术,可以快速的识别图像中的文字,并且将其转换成文本,支持超过60种语言。不过软件不像其他的安装类软件,软件在安装之后还需要配置才可以使用了
tesseract-ocr官方下载据说曾经的图像识别能力排名第三。tesseract-ocr中文版可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护,目前发布在Googel project上。
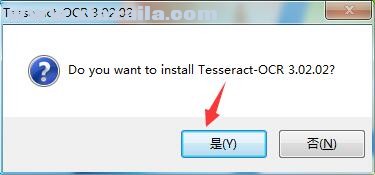
1、双击安装文件,弹出如图窗口,点击是表示同意安装
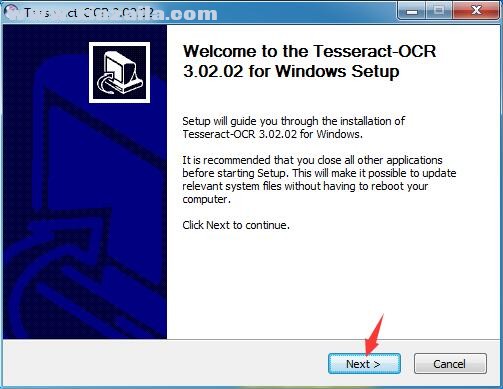
2、进入安装向导界面,点击next
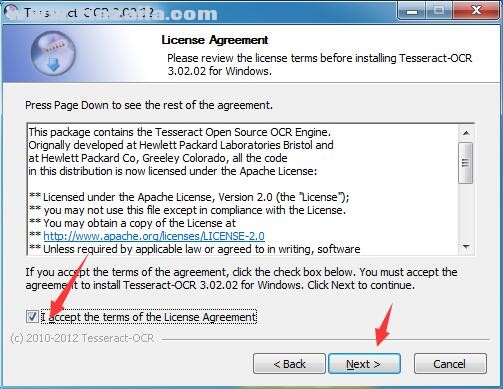
3、阅读软件的许可协议,勾选I accept...
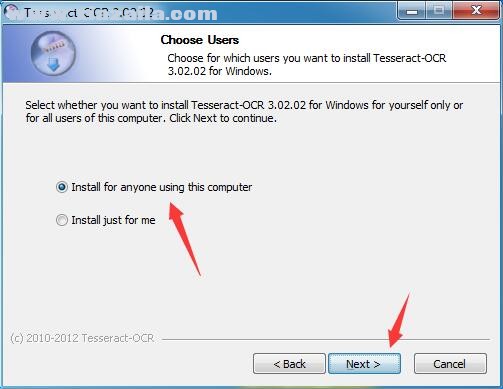
4、选择安装方法
5、选择安装位置,默认是C:Program Files (x86)Tesseract-OCR,可以点击browse修改
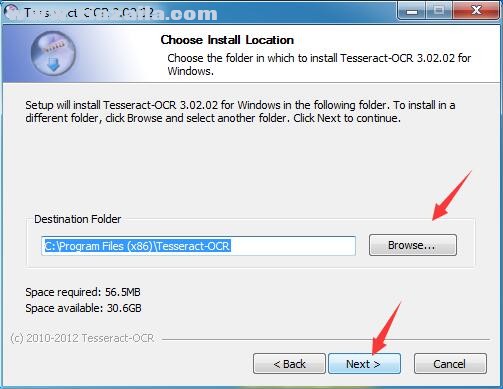
6、勾选附加选项
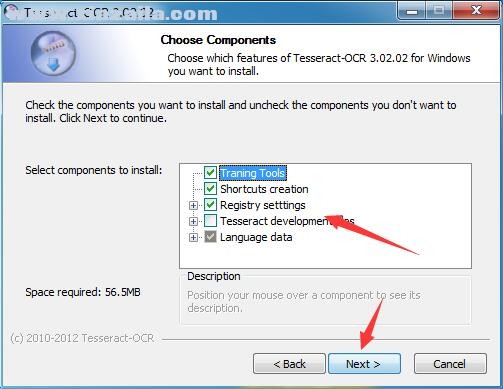
7、选择开始菜单文件夹,点击install开始安装
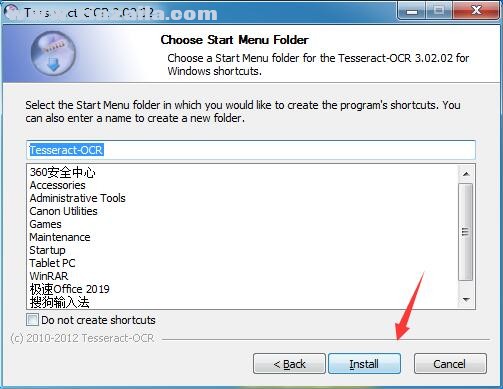
8、安装完成
1、添加环境变量
将Tesseract-OCR安装目录加入环境变量,
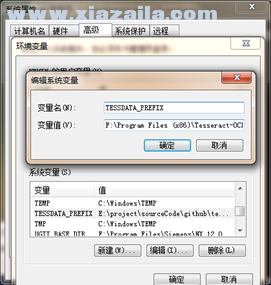
变量名TESSDATA_PREFIX
变量值F:Program Files (x86)Tesseract-OCRtessdata
2、测试
将以下图片保存为test.jpg,然后放在E盘根目录下

在cmd窗口中执行 tesseract test.jpg test.txt –l chi_sim+eng(chi_sim是中文识别包,equ是数学公式包,eng是英文包),即可将图片中的文字识别出来,识别结果如下:

下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下:
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。
使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract:
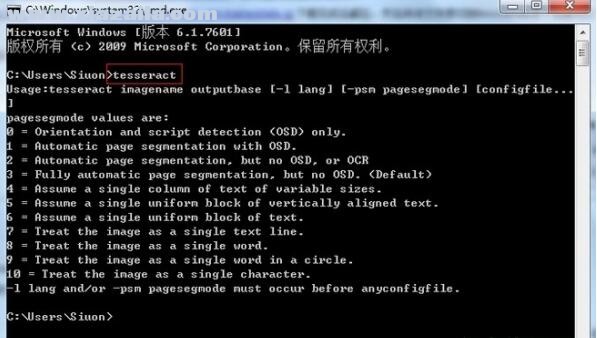
如果出现如上输出,表示安装正常。
我准备了一张验证码
放在D盘根目录下,上图:
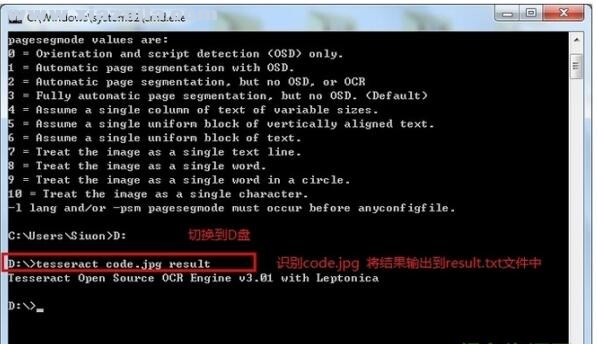
这样就可以得出识别结果了
Copyright © 2018-2019 www.xiazaila.com. All Rights Reserved .
本站内容来源网络,均为用户提交发布或各大厂商提交,如有内容侵犯您的版权或其他利益的,请来信告知我们。










 濠通屏幕识文
濠通屏幕识文 极速文本去重复软件
极速文本去重复软件 论文浅搜对比器
论文浅搜对比器 任性写日记
任性写日记 码字精灵
码字精灵 Visual Notes
Visual Notes
软件评论 您的评论需要经过审核才能显示
网友评论